How Machine Learning Is Changing Synthetic Biology
Bedbrook and colleagues at Arnold’s Lab at the California Institute of Technology is bringing machine learning to synthetic biology.
Twist Bioscience
December 12, 2017
9 min read
Have you accessed social media, or used a digital streaming service recently? If you have, there’s a good chance your experience of these services has been enhanced by machine learning. Machine learning is a type of computer programming, in which the computer can learn about the appropriate response in a complex situation by taking on lots of information. It then uses this information to make decisions when posed with a new problem.
Machine learning is already prevalent in our everyday lives. Music streaming services like Spotify pay attention to the songs you like to listen to, and with this information can curate playlists containing new music that matches what you like. On the other hand, electric car manufacturer Tesla has used machine learning to teach their cars how to drive. You might have seen the videos online of Tesla cars responding to hazards on the road before humans are aware of a problem arising.
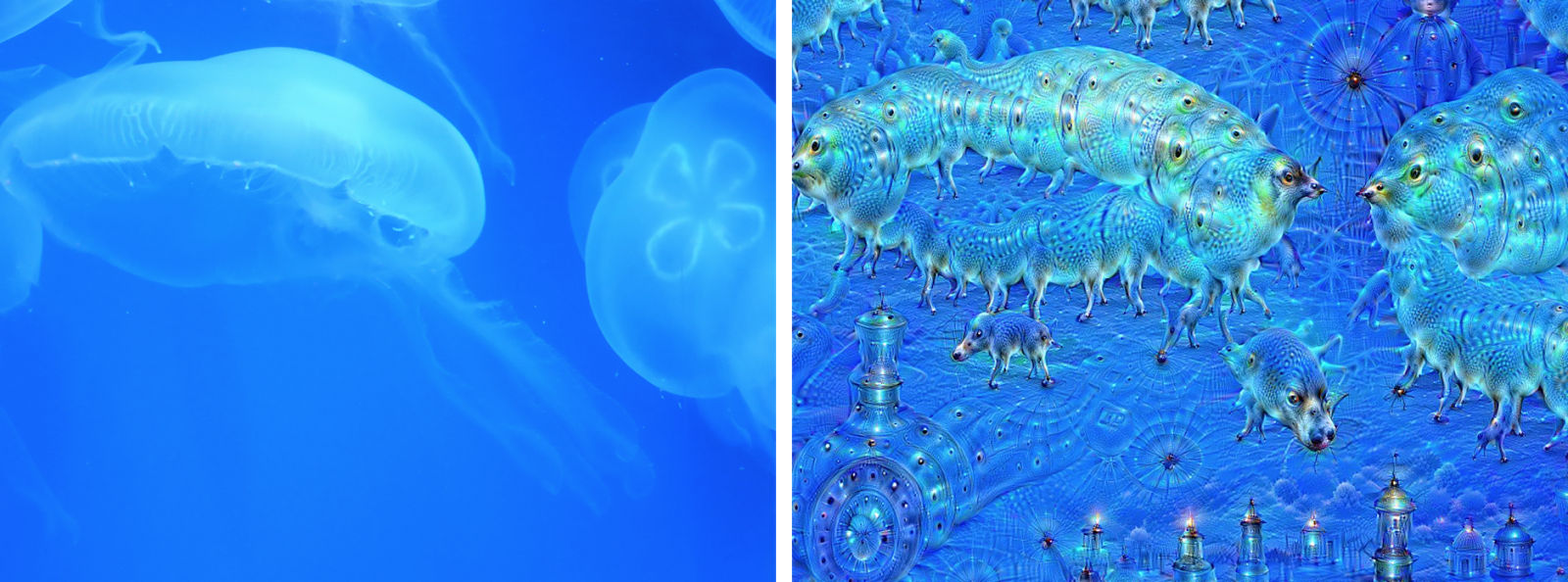
Google engineer Alexander Mordvinstev’s deep dream algorithm: Machine learning is used to teach a computer about a given set of images, and the computer will then find and enhance any parts of these images it finds in any photo, creating psychedelic digital art. Left is an image of jellyfish, right is the same image enhanced by deep dream algorithm trained with images of animals and buildings. Source: Wikicommons. Author: MartinThoma
A recent study by Bedbrook and Yang et al. from Professor Frances Arnold’s Lab at the California Institute of Technology is bringing machine learning to synthetic biology. The team applied machine learning to the challenge of protein engineering, specifically the engineering of an integral membrane protein called a channelrhodopsin. By teaching a computer about the relationship between this protein’s structure and its function, the team was able to predict channelrhodopsin properties from their sequence, and used this to enable the engineering of entirely new protein variants.
Channelrhodopsins are important biomedical research tools and are a key example of applied synthetic biology. In nature, channelrhodopsins are the “eyes” of photosynthetic microorganisms. These proteins integrate into the outer layer of algae forming minute channels that use light and a molecule similar to vitamin A to open and close, controlling the flow of ionic particles in and out of the cell.
In 2005, researchers, including Neuroscientist Ed Boyden, Feng Zhang now of CRISPR fame and Viviana Gradinaru, working in Professor Karl Deisseroth’s lab at Stanford, showed that when channelrhodopsins are engineered to express in an animal’s neuronal cells, a neuronal impulse can be activated by light! This works because the neuronal impulse is an electrical signal that travels down the neuron caused by a chain reaction of ion channels opening and closing. Expressed channelrhodopsins act as a starter motor for this chain reaction, giving researchers control over neuronal impulses.
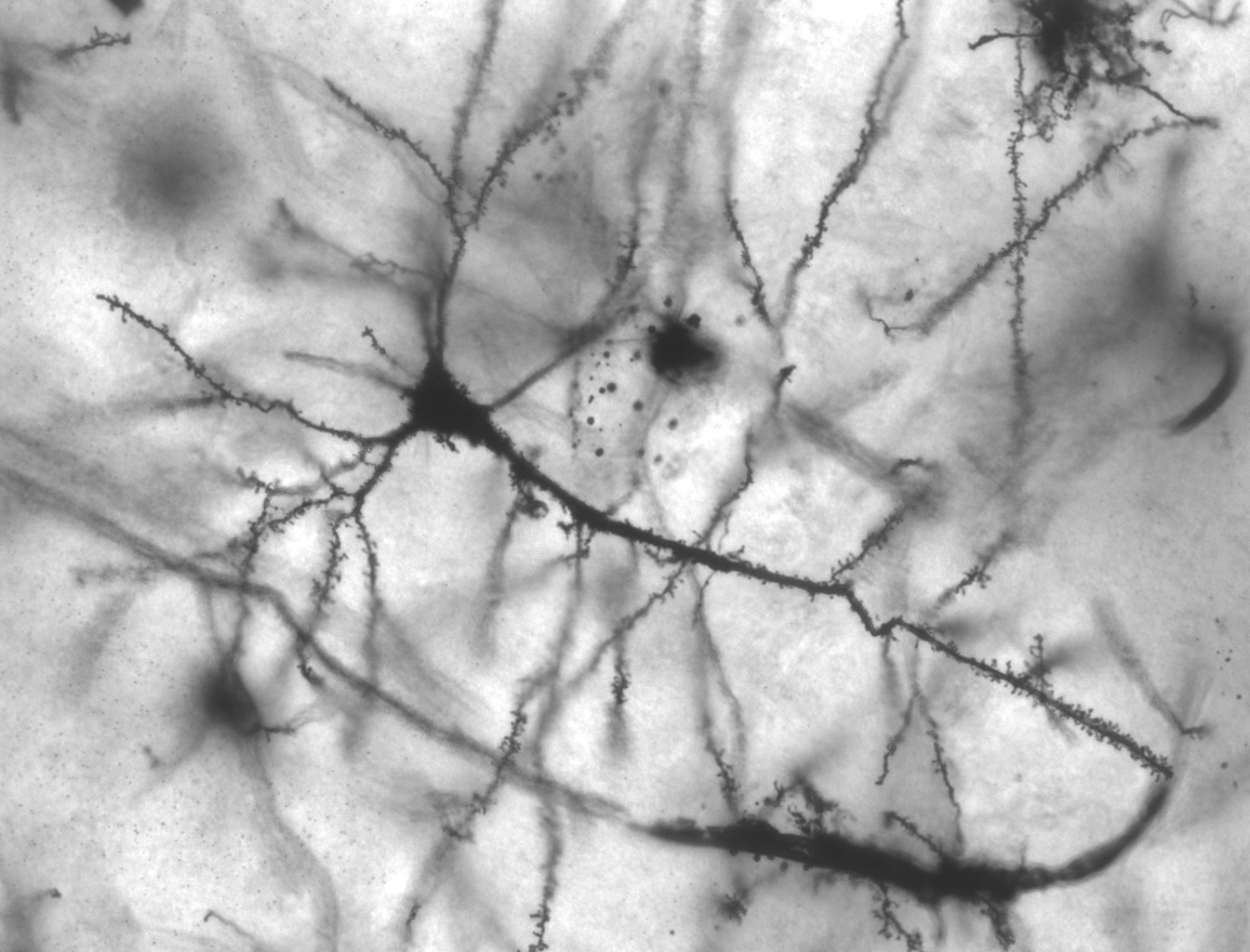
Neurons like the one in this image can have their impulses activated by engineered algal channelrhodopsins Source: wikicommons. Author: Methoxyroxy
This discovery kicked off the entire field of optogenetics - the use of light to control and study living cells. Today, optogenetics is being used to control neurons in freely living animals, and is providing great insight into exactly how our brains are wired at the neuronal level. Optogenetics has already begun to unravel important neural circuit signatures for disorders such as autism and schizophrenia.
In the new study by Arnold’s lab, the authors describe how channelrhodopsins are also problematic for the field of optogenetics. The proteins must be integrated into the membrane, and localize to the correct location to be functional. To get the protein where it is needed, the cell must undergo a complex process of protein folding and multi-step trafficking.
Additionally, only a small number of natural, well-characterized channelrhodopsins exist, and they often produce only weak signals, are readily inactivated, or have a limited wavelength spectra for activation. It is therefore desirable to engineer channelrhodopsins in an effort to improve the tools available to optogenetics experts by creating new molecules with robust cellular trafficking, novel activity or improved functionality.
Until now, engineering these proteins has proved difficult. As soon as researchers had tried to change the amino acid sequence of the channelrhodopsin, localization or activity were impaired. It is evident that much of the protein’s complex trafficking process is influenced, often unpredictably, by its amino acid sequence and its 3D structure.
It is this complex problem Bedbrook and colleagues tackled with machine learning.
Members of the Arnold Lab involved in this study. Left to right: Austin Rice, Claire Bedbrook, Kevin Yang
They asked whether it is possible to use a channelrhodopsin’s sequence and structure to effectively teach a computer how to predict whether the protein will localize correctly and express well.
To perform this study, the researchers first had to generate a training dataset describing the relationship between channelrhodopsin amino acid sequence, and channelrhodopsin expression and localization.
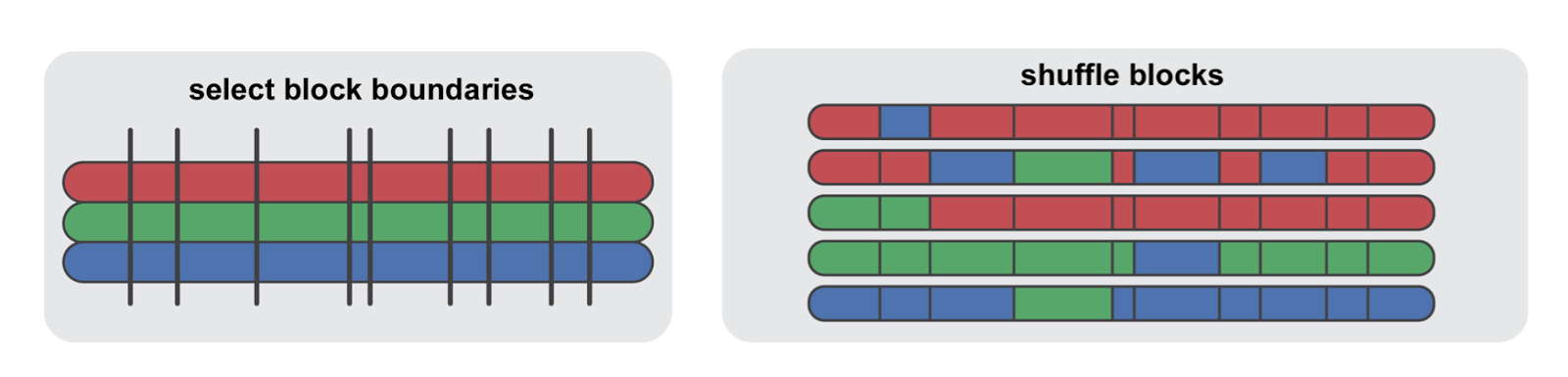
In previous work, Arnold’s lab used a method called structure-guided SCHEMA recombination to generate a huge library of channelrhodopsin variant sequences. This process uses an algorithm called SCHEMA to find blocks of protein sequence that if swapped out, are unlikely to impair protein folding, and by extension damage protein function. These blocks of optimal sequence were then shuffled between three different channelrhodopsins. The team used next-generation DNA synthesis from Twist Bioscience to build around 200 new channelrhodopsins, and upon characterization showed that many of these new proteins showed good localization. (Frances Arnold is a member of Twist Bioscience’s Scientific Advisory Board.)
Structure-guided SCHEMA recombination allows for the formation of huge libraries of sequence variants, in which each protein variant has a high likelihood of expression and activity. Figure modified from Bedbrook et al., 2017
The team then took these sequences and compared them all to one another, measuring both amino acid sequence similarity and structural similarity, producing a detailed map of the relationship between sequence and function. The activities, similarities and structural information of these 200 sequences formed the dataset they would train their model on.
Once training was complete, their model could take a channelrhodopsin amino acid sequence, and output predictions of whether the sequence would show good or bad expression, good or bad localization and the level of correct localization the amino acid sequence would show, all based on what the model had learned about sequence-function relationships.
Next, the researchers sought to explore the accuracy their model. By again using next-generation DNA synthesis from Twist Bioscience to generate a set of channelrhodopsin sequences predicted to have a range of properties, and testing their properties empirically, the team generated a new dataset also describing sequence-function relationships. The results of this validation were then fed back into the model in a subsequent round of training.
This is the iterative nature of machine learning, in which the accuracy of the computer’s predictions can be constantly improved as the computer learns more about its own performance. The final model produced by the team could accurately predict which sequences in their original SCHEMA library would have very high rates of correct localization and therefore be useful proteins for optogenetics. Shockingly, only five percent of the original library would have displayed desirable properties, therefore highlighting the importance of machine learning when engineering tricky enzymes like channelrhodopsins, who’s requirements for functionality are highly complex.
In an interview with the study’s authors, Kevin Yang stated that this machine learning model works so well as the final product “picks mutations intelligently instead of randomly,” and went on to say that his team hopes that “there will be a move to the use of machine learning in the community, especially when other forms of protein engineering aren’t possible”.
Claire Bedbrook also discussed how next generation DNA synthesis from Twist Bioscience had made their study possible: “If we were to build the sequences we used in this study with traditional methods, the cloning would take an incredibly long time. We would have to construct each sequence independently out of the blocks. It wouldn’t be possible.” Twist Bioscience offers high throughput DNA synthesis that can be purchased pre-cloned and ready to use in experiments straight out of the parcel.
Yang continued, saying “machine learning is iterative, and as a result many sequences have to be generated regularly, we used around 300 sequences in this study. Anything our model predicts, we can make with Twist Bioscience”. Finally, Bedbrook mentioned “the fact sequences arrive from Twist Bioscience with their sequence already verified means we can be absolutely sure that any property we measure has a direct relationship with its sequence,” an essential property for this method to work.
It is no question that this study is groundbreaking, both for optogenetics and for protein engineering. Bedbrook and Yang mentioned they have already started testing some of their newly engineered channelrhodopsins in neurons, and preliminary results look promising! Machine learning is very new to synthetic biology, with only a handful of published examples. However, the team behind this study has shown that with the help of next generation DNA synthesis, machine learning is set to become an integral application for protein engineering in the near future.
Cover image source: Wikicommons. Author: Wei-Chung Allen Li et al.



{kind=link}