超高通量测序的简化工作流程
Twist 的 FlexPrepTM UHT 文库制备试剂盒为群体研究、农业基因组学和其他超高通量应用提供了传统基于微阵列技术的新一代测序替代方案。通过将 Twist 的 Normalization by LigationTM (NBL) 技术与酶切片段化相结合,试剂盒可对各种 DNA 起始量进行内置的样本归一化处理,从而降低了典型样本处理步骤的成本和复杂性。早期的样本条形码可将 12 个独立样本汇集到一个反应中,从而简化工作流程,提高效率。



仅供研究使用。不适用于任何诊断或临床程序。
*基于 8 与 96 孔工作流程
探索 Twist 的超高通量测序方法
超高通量测序的简化工作流程
Twist 的 FlexPrepTM UHT 文库制备试剂盒为群体研究、农业基因组学和其他超高通量应用提供了传统基于微阵列技术的新一代测序替代方案。通过将 Twist 的 Normalization by LigationTM (NBL) 技术与酶切片段化相结合,试剂盒可对各种 DNA 起始量进行内置的样本归一化处理,从而降低了典型样本处理步骤的成本和复杂性。早期的样本条形码可将 12 个独立样本汇集到一个反应中,从而简化工作流程,提高效率。
探索 Twist 的超高通量测序方法
仅供研究使用。不适用于任何诊断或临床程序。
*基于 8 与 96 孔工作流程
常见问题解答
Twist FlexPrepTM UHT 文库制备试剂盒采用了一种新的 Normalization by LigationTM 方法,无需进行 前期和中期样本定量,简化了您的测序工作流程。
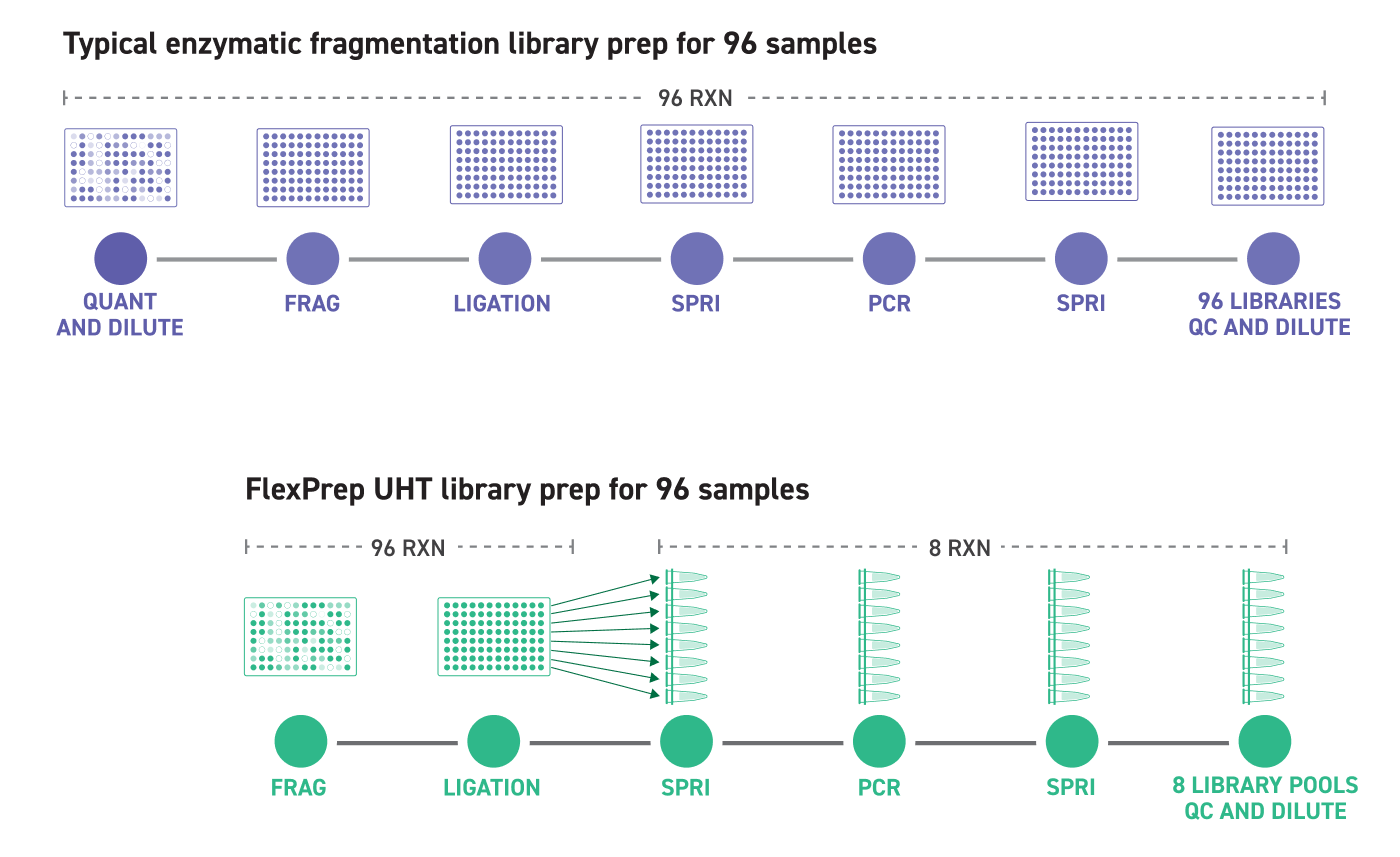
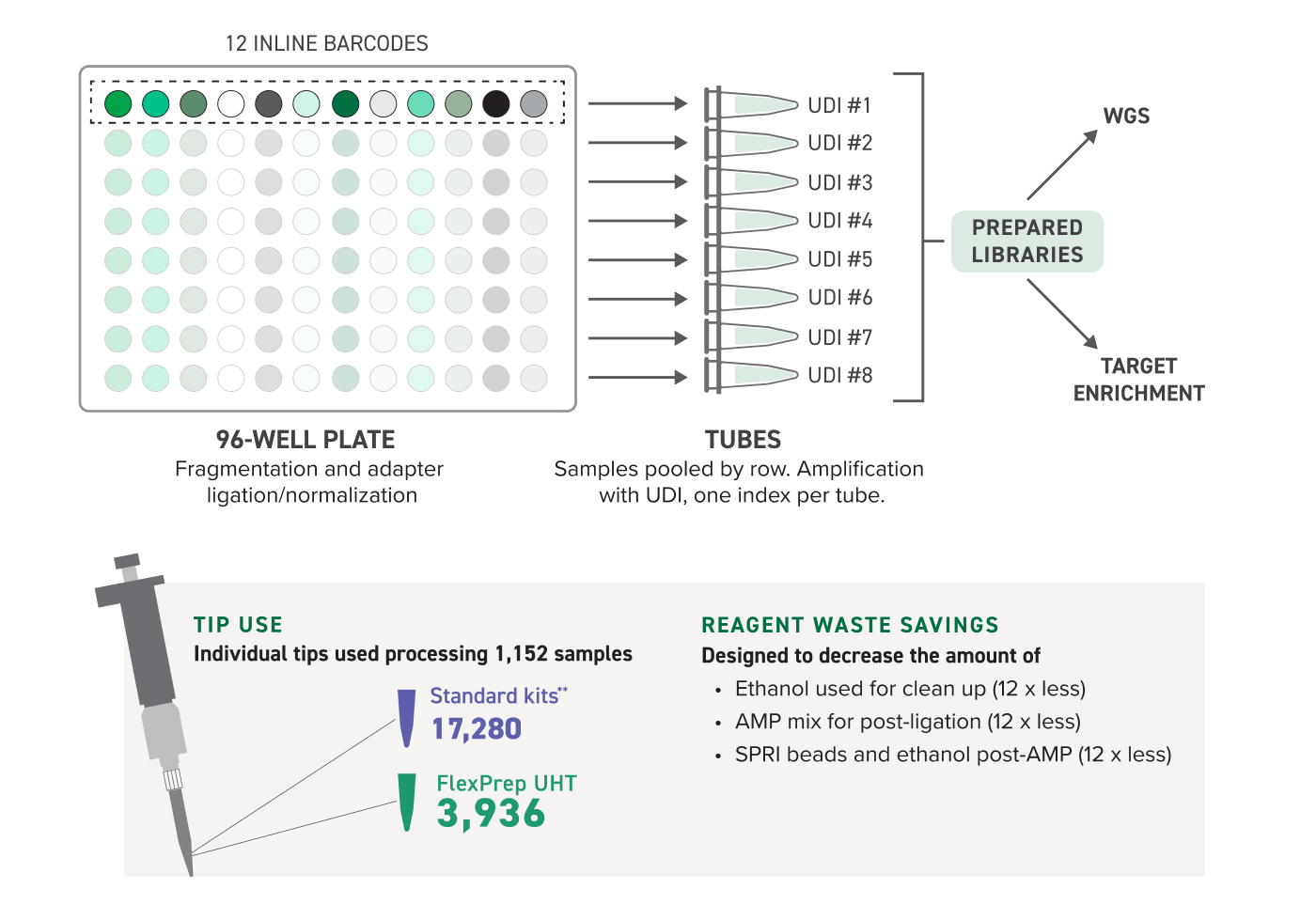
在一个孔中为一个样本制备片段化和连接反应。在连接过程中使用的接头包含嵌入条形码,允许将所有 12 个孔合并为 96 孔板的一排。单个池通过 PCR 添加标签 (UDI) 制备,由此进行池级拆分。通过在一个试剂盒的单次测序运行中运行多达 1,152 个样本,可充分提高测序通量。这一效率的提高还可转化为节省成本和耗材。
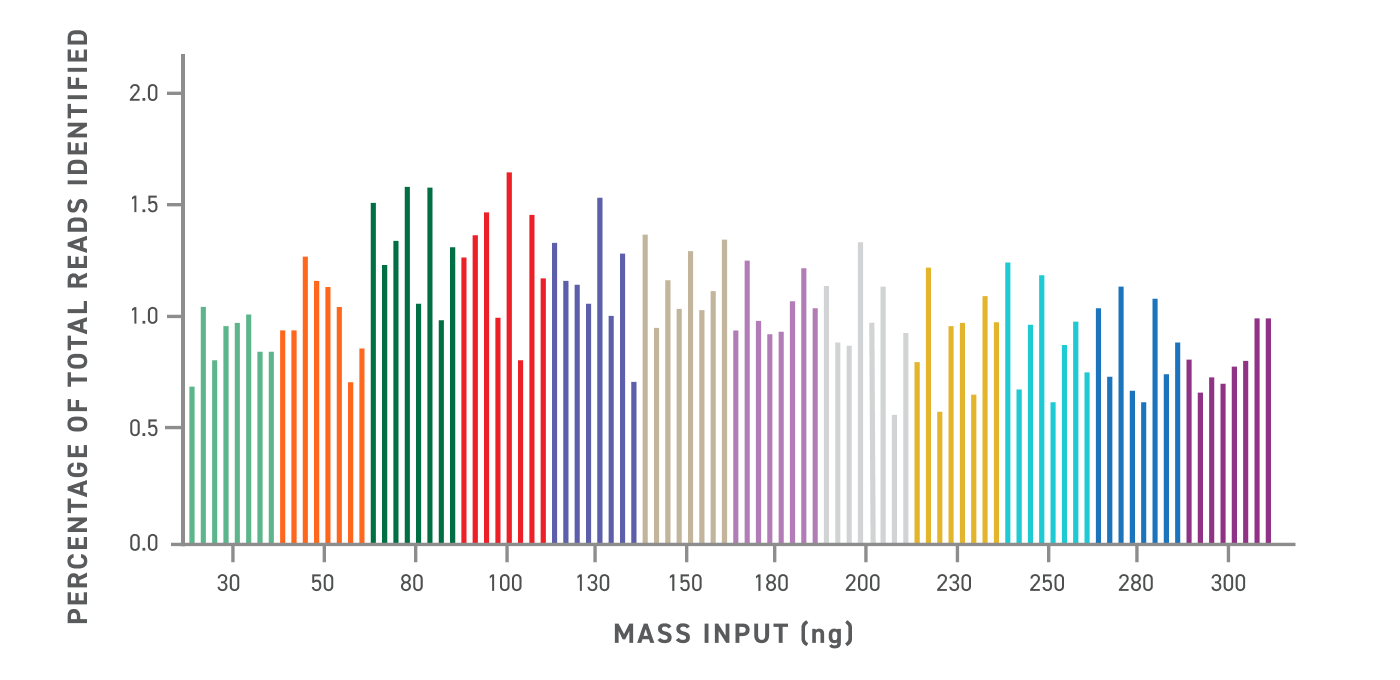
输入不同 DNA 质量的新一代测序读数深度归一化。每个文库识别的总测序片段计数的百分比是在按双端唯一标签和嵌入条形码拆分后计算的。完全归一化后的平均值估计为 1.04% (100/96)。
FlexPrep UHT 生成的高复杂度文库在靶向富集后具有均一覆盖度。FlexPrep 与 Twist 定制组合相结合,支持以可调覆盖深度测序 SNP、k-mer、结构变异和其他基因组目标区域。对富集材料进行测序后,将数据截取至平均 75x 的覆盖度。报告了 Picard 的关键靶向富集指标。
在文库制备中使用 96-plex30 ng 至 300 ng gDNA 起始量进行靶向富集 |
|
在 75x 原始靶标覆盖度下的指标 |
平均 +/- 标准差 |
选定碱基平均靶向覆盖度嵌合体Fold 80 碱基罚分覆盖度为 10X 的碱基覆盖度为 20X 的碱基覆盖度为 0X 的碱基 |
79.22% +/- 0.54%32.74 +/- 4.781.31% +/- 0.38%1.416 +/- 0.04496.06% +/- 0.94%85.41% +/- 6.36%0.43% +/- 0.04% |
*使用的方法:在 Illumina NextSeq 550 上测序之前,使用 Twist FlexPrep UHT 文库制备试剂盒和 FlexPrep 靶向富集实验方案(用一个定制的 800kb 组合进行 96-plex 富集),用人类基因组 DNA (gDNA) (NA12878) 制备 96 个文库。在各个混合文库中,使用 30 ng 至 300 ng 的可变起始量生成了 8 个混合文库,每个混合文库包含 12 个样本。**标准试剂盒基于依次使用酶切片段化、连接和 PCR 的工作流程 ***所有图表、数字和图基于 2024 年 9 月的 Twist 内部数据。仅供研究使用。不适用于任何诊断或临床程序。
Twist FlexPrepTM UHT 文库制备试剂盒采用了一种新的 Normalization by LigationTM 方法,无需进行 前期和中期样本定量,简化了您的测序工作流程。
在一个孔中为一个样本制备片段化和连接反应。在连接过程中使用的接头包含嵌入条形码,允许将所有 12 个孔合并为 96 孔板的一排。单个池通过 PCR 添加标签 (UDI) 制备,由此进行池级拆分。通过在一个试剂盒的单次测序运行中运行多达 1,152 个样本,可充分提高测序通量。这一效率的提高还可转化为节省成本和耗材。
输入不同 DNA 质量的新一代测序读数深度归一化。每个文库识别的总测序片段计数的百分比是在按双端唯一标签和嵌入条形码拆分后计算的。完全归一化后的平均值估计为 1.04% (100/96)。
FlexPrep UHT 生成的高复杂度文库在靶向富集后具有均一覆盖度。FlexPrep 与 Twist 定制组合相结合,支持以可调覆盖深度测序 SNP、k-mer、结构变异和其他基因组目标区域。对富集材料进行测序后,将数据截取至平均 75x 的覆盖度。报告了 Picard 的关键靶向富集指标。
在文库制备中使用 96-plex30 ng 至 300 ng gDNA 起始量进行靶向富集 |
|
在 75x 原始靶标覆盖度下的指标 |
平均 +/- 标准差 |
选定碱基平均靶向覆盖度嵌合体Fold 80 碱基罚分覆盖度为 10X 的碱基覆盖度为 20X 的碱基覆盖度为 0X 的碱基 |
79.22% +/- 0.54%32.74 +/- 4.781.31% +/- 0.38%1.416 +/- 0.04496.06% +/- 0.94%85.41% +/- 6.36%0.43% +/- 0.04% |
*使用的方法:在 Illumina NextSeq 550 上测序之前,使用 Twist FlexPrep UHT 文库制备试剂盒和 FlexPrep 靶向富集实验方案(用一个定制的 800kb 组合进行 96-plex 富集),用人类基因组 DNA (gDNA) (NA12878) 制备 96 个文库。在各个混合文库中,使用 30 ng 至 300 ng 的可变起始量生成了 8 个混合文库,每个混合文库包含 12 个样本。**标准试剂盒基于依次使用酶切片段化、连接和 PCR 的工作流程 ***所有图表、数字和图基于 2024 年 9 月的 Twist 内部数据。仅供研究使用。不适用于任何诊断或临床程序。
通过用于低通测序的 FlexPrep™ UHT 文库制备试剂盒和用于简化分析的 Curio Genomics,来扩大您的农业基因组学研究规模。借助 Curio Genomics 平台,Twist 灵活的文库制备无缝集成,提供高通量处理和高效填充,从而能够在大量群体中实现经济高效的基因分型。
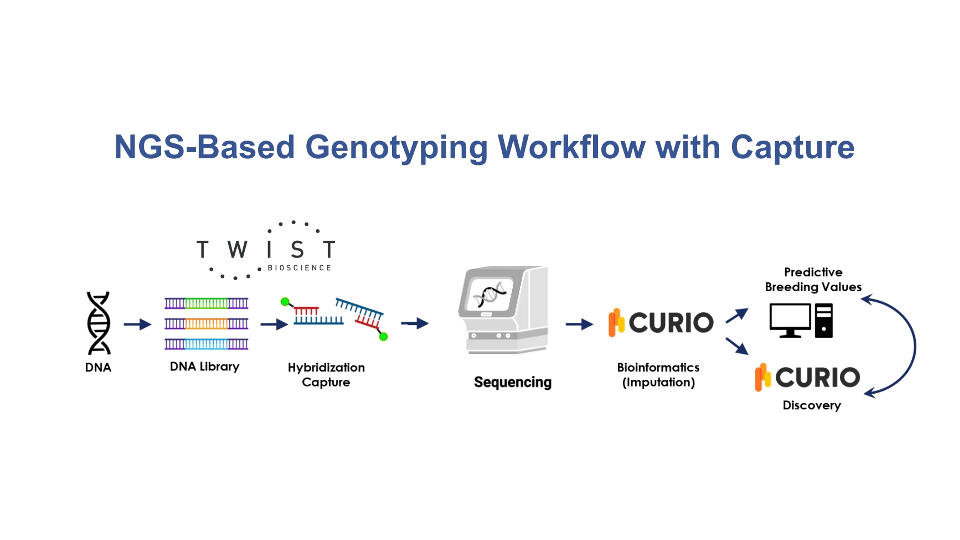
为了简化人类群体基因组学,将 FlexPrep™ UHT 文库制备试剂盒与 Gencove 的强大分析工具进行了结合。Twist 的创新型文库制备采用了 Normalization By Ligation™ (NBL),消除了瓶颈问题,与此同时 Gencove 的填充流程可从减少的测序覆盖度中实现高置信度的变异检出,最大限度地提高效率和通量,使您能够从基因分型数据中获得有价值的见解,同时具有极高的准确性并降低测序成本。

通过用于低通测序的 FlexPrep™ UHT 文库制备试剂盒和用于简化分析的 Curio Genomics,来扩大您的农业基因组学研究规模。借助 Curio Genomics 平台,Twist 灵活的文库制备无缝集成,提供高通量处理和高效填充,从而能够在大量群体中实现经济高效的基因分型。
为了简化人类群体基因组学,将 FlexPrep™ UHT 文库制备试剂盒与 Gencove 的强大分析工具进行了结合。Twist 的创新型文库制备采用了 Normalization By Ligation™ (NBL),消除了瓶颈问题,与此同时 Gencove 的填充流程可从减少的测序覆盖度中实现高置信度的变异检出,最大限度地提高效率和通量,使您能够从基因分型数据中获得有价值的见解,同时具有极高的准确性并降低测序成本。
109220
Twist FlexPrep™ UHT 文库制备试剂盒,192 个样本109223
Twist FlexPrep™ UHT LP 和杂交试剂盒,192 个样本109224
Twist FlexPrep™ UHT 文库制备试剂盒,1152 个样本109226
Twist FlexPrep™ UHT LP 和杂交试剂盒,1152 个样本109220
Twist FlexPrep™ UHT 文库制备试剂盒,192 个样本109223
Twist FlexPrep™ UHT LP 和杂交试剂盒,192 个样本109224
Twist FlexPrep™ UHT 文库制备试剂盒,1152 个样本109226
Twist FlexPrep™ UHT LP 和杂交试剂盒,1152 个样本 产品说明书
产品说明书
 应用说明
应用说明
 方案
方案
 技术文档
技术文档
 海报
海报

