Multiplexed Gene Fragments: A Key To Better High-Throughput Screening

When an experiment is just an idea, its practical limitations are easily overshadowed by the alluring potential of discovery. It’s hard to appreciate how the imperfect realities of lab work can add up, especially when it seems so reasonable to just add a few more samples into the mix, a few more variables, and maybe an extra step or two. But when it comes time to load the pipette and set the experiment in motion, the truth becomes clear: doing less is frequently the best way to achieve more.
This is particularly true in the context of high-throughput screening, where researchers must often go through the laborious process of assembling long pieces of double stranded DNA (dsDNA) from smaller synthetic oligonucleotides. Conceptually, the process is simple: synthesize the thousands to hundreds-of-thousands of needed oligonucleotides, convert these into a dsDNA format, clone them into a vector, and deliver them to target cells for expression and downstream screening. Such is the basis of many high-throughput applications, from massively parallel reporter assays (MPRA) to large-scale antibody development projects. While the idea of high-throughput screening is simple, the practical implementation is anything but.
A subtle and yet significant hurdle that researchers face with these projects is the need for pooled DNA fragment synthesis. Individual segments of dsDNA can be constructed through routine methods, but these techniques don’t easily scale. When thousands of distinct dsDNA fragments are needed, as in high-throughput screening, researchers must rely on the severely limited process of pooled dsDNA synthesis.
"Twist’s MGF are here to help you do less while achieving more"
Historically, to reliably produce large quantities of pooled DNA fragments, manufacturers had to pare the size of the fragment down to just 150 to 300 base pairs in length. This means that, for most applications, researchers have to stitch multiple DNA fragments together to create their desired sequence, be it a gene, antibody variable region, or tandem guide RNAs. Doing so adds complexity and resource constraints that can curtail the scale, efficiency, and impact of screening projects.
Put simply, the limits of creating pooled synthetic DNA fragments force researchers to do more during experimental setup for a less than ideal return. This is where Twist’s Multiplex Gene Fragments (MGF) can help. With MGF, Twist now provides pooled, customized, double-stranded DNA fragments between 301 and 500 base pairs in length that are made using direct synthesis, with practically unlimited potential to scale. By providing added length and scale in multiplexed dsDNA synthesis, MGF represents a significant leap forward in the field.
Pushing the Boundaries of DNA Synthesis
The added benefits provided by MGF open up new and important possibilities for researchers. One of the most exciting applications lies in antibody discovery and development. Antibodies, with their unique ability to bind to specific antigens, are crucial in both therapeutic and diagnostic settings. A key focus area in antibody engineering is the optimization of complementarity-determining regions (CDRs), wherein subtle changes to amino acid sequence can significantly alter epitope binding kinetics.
💻 The Power of AI/ML in Antibody Development
AI and ML have already begun transforming various scientific fields, and antibody development is no exception. By analyzing vast datasets, these technologies can identify patterns and predict which antibody sequences are most likely to succeed. AI/ML-informed libraries are considerably smaller than conventional libraries, which often contain millions of variants. Instead, these smarter libraries might include only thousands of variants, each carefully selected for its potential efficacy.
To see how Twist’s MGF can support antibody development, read this recent preprint from the University of Washington's Baker lab: Atomically accurate de novo design of single-domain antibodies.
Traditionally, antibody discovery and optimization has involved the creation of expansive variant libraries for large-scale screening. To do so, libraries are assembled by synthesizing and connecting short DNA fragments in various combinations. Such a process, while effective, introduces a degree of randomness that prevents perfect control over which variants are created and in what quantities.
This lack of control is particularly disruptive during the optimization process, where researchers have already identified candidate antibodies and wish to hone candidate properties by making rational changes to CDR sequences. With artificial intelligence (AI) and machine learning (ML) software, the design of these libraries is increasingly refined, allowing researchers to narrow the scope of the screen to an enriched pool of candidates. However, with traditional approaches to library synthesis, creating a narrowly defined pool was a challenging task and came with the risk of variant under-representation.
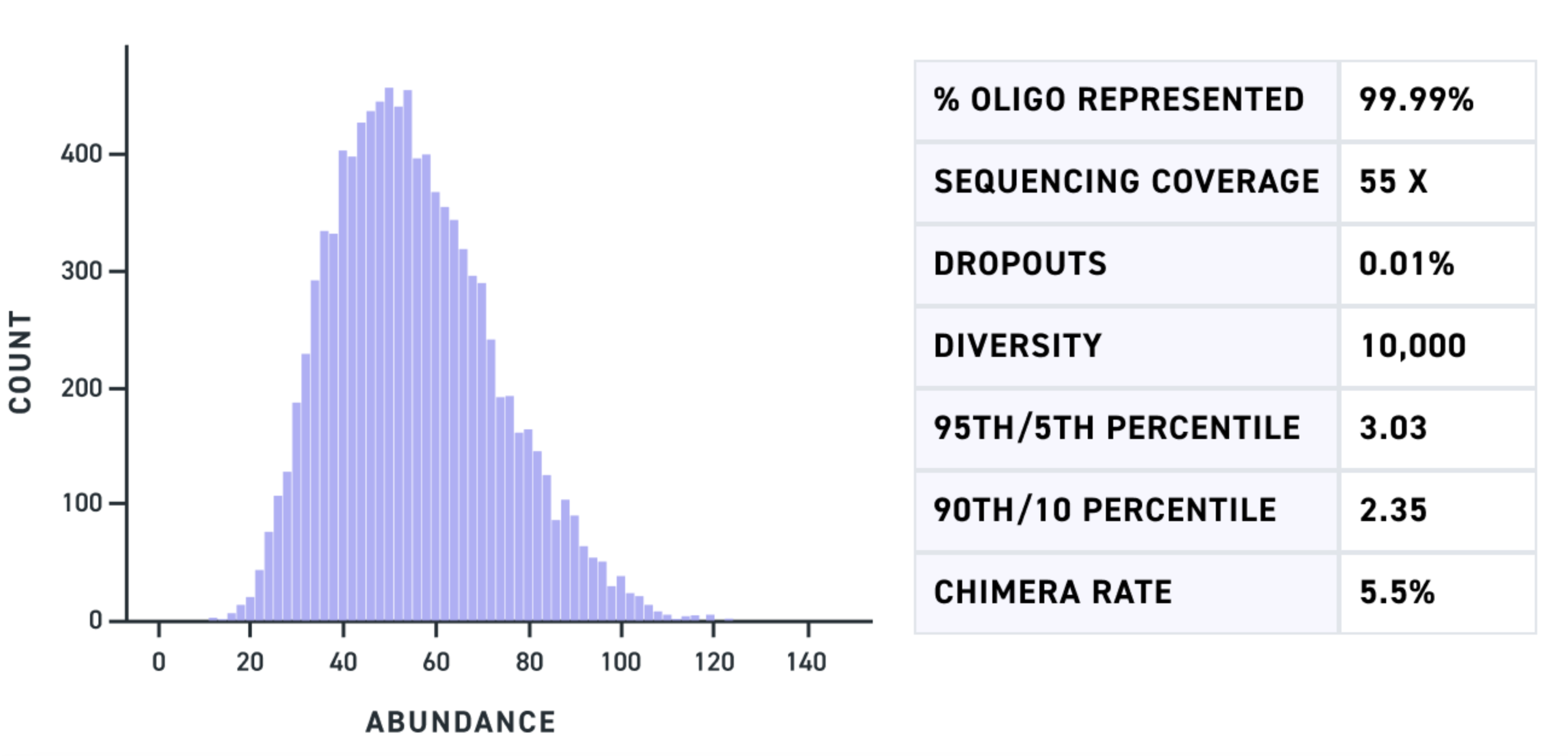
Fortunately, antibody variable regions—where CDRs are located—are roughly 400-450 bp in length. With direct synthesis of fragments of up to 500 bp, MGF enables researchers to encode entire antibody variable regions, including all three CDRs, in a single fragment. This level of control allows for the highly precise design and synthesis of antibody variant libraries. Twist’s MGF pools achieve comprehensive representation of every sequence ordered, ensuring precise control over variant construction for more targeted and rational screening (Figure 1). And, with high resolution control over CDR sequences, researchers can reduce the size of their screening pool to match AI/ML designs, ultimately opening the door to far more efficient and productive screening.
Expanding Screening Horizons
The advantages of MGF extend beyond antibody development. Researchers involved in mRNA screening with massively parallel reporter assays can also reap significant benefit. mRNA screening often requires the study of non-coding regulatory elements—such as untranslated regions (UTRs)—that may influence mRNA dynamics. Importantly, UTRs are frequently longer than 200 base pairs. With MGF, synthesizing these DNA screening pools becomes straightforward, facilitating more control over assay design and, as with antibody optimization, enabling efficient research.
Moreover, MGF opens new doors in the realm of CRISPR technology.
CRISPR, a powerful tool for gene editing, relies on guide RNAs that target Cas enzymes to specific DNA or RNA sequences. In recent years, the need for longer DNA fragments has steadily grown1 (see our in depth exploration of The Changing CRISPR Landscape). Researchers may wish to encode multiple guide RNAs in a single cassette, with each targeting the same gene to increase knockout efficacy. Alternatively, multiple guides may be used to simultaneously perturb different genes, exposing potential epistatic relationships and synthetic lethal combinations2. Others are interested in more advanced applications of CRISPR technology to perform PRIME editing, wherein endogenous sequences are replaced with a synthetically designed—and typically long—DNA sequence3,4.
In each use case, it’s critical that CRISPR cassettes (carrying the guide RNAs, template DNA, reporters, or other elements) be precisely synthesized. Even single base errors can diminish the success of genomic editing and lead to erroneous conclusions. MGF’s ability to produce longer DNA fragments in a pooled format, while maintaining high accuracy and uniformity (Figure 1), allows for the inclusion of multiple guide RNAs (4-6) within a single 500bp fragment. The result is greater precision and potential in advanced CRISPR screening applications, from multi-guide delivery to PRIME editing.
🤔The Challenge and Value of Scale
In-house assembly is a traditional laboratory process that has enabled researchers to piece together custom DNA sequences for decades. However, the process can be cumbersome and costly when large pools of fragments are necessary for research. This reality means that creating libraries that are thousands to millions of fragments deep may be impossible for most labs, if not impractical.
Twist’s MGF help to alleviate this pain by reducing the need for fragment assembly, providing long DNA fragments with seemingly endless scale. Twist’s DNA synthesis platform makes it possible to rapidly synthesize thousands to hundreds-of-thousands of pooled gene fragments with industrial capacity, meaning there is no limit to the number of gene fragments that can be included in a high-throughput screen, resulting in a seemingly endless number of applications enabled by MGF.
Practical Implications and Future Prospects
The introduction of Twist’s Multiplexed Gene Fragments is a significant step forward for the field of molecular biology. By enabling the direct synthesis of pooled dsDNA fragments up to 500bp in length with high precision, Twist’s MGF simplify complex workflows and reduce the potential for costly errors. Researchers can now focus on the creative and innovative aspects of their work, rather than being bogged down by technical limitations and inefficiencies. As the scientific community continues to explore the potential of MGF, the applications of this new tool are likely to expand, driving further innovation and discovery.
It is tempting to design complex experiments that involve in-house assembly. And it is doable. But every added step comes with a cost, be it time, resources, or the potential for errors. In this case, doing more can have diminishing returns. Twist’s MGF are here to help you do less and achieve more.
Referencias bibliográficas
- Herring-Nicholas, Ashley, et al. “Selection of Extended CRISPR RNAs with Enhanced Targeting and Specificity.” Communications Biology, vol. 7, no. 1, 12 Jan. 2024, pp. 1–9, www.nature.com/articles/s42003-024-05776-8, https://doi.org/10.1038/s42003-024-05776-8.
- Replogle, Joseph M., et al. “Combinatorial Single-Cell CRISPR Screens by Direct Guide RNA Capture and Targeted Sequencing.” Nature Biotechnology, vol. 38, no. 8, 30 Mar. 2020, pp. 954–961, https://doi.org/10.1038/s41587-020-0470-y.
- Koeppel, Jonas, et al. “Prediction of Prime Editing Insertion Efficiencies Using Sequence Features and DNA Repair Determinants.” Nature Biotechnology, 16 Feb. 2023, pp. 1–11, www.nature.com/articles/s41587-023-01678-y, https://doi.org/10.1038/s41587-023-01678-y.
- Ren, Xingjie, et al. “High-Throughput PRIME-Editing Screens Identify Functional DNA Variants in the Human Genome.” Molecular Cell, vol. 83, no. 24, 1 Dec. 2023, pp. 4633-4645.e9, https://doi.org/10.1016/j.molcel.2023.11.021.
¿Qué piensa?
Me gusta
No me gusta
Me encanta
Me asombra
Me interesa

