DNA Data Storage – Setting the Data Density Record with DNA Fountain
Three thousand zettabytes. This monstrous amount is the conservative projection for the volume of all the world’s existing data by 2040.
Twist Bioscience
12 de diciembre de 2017
Lectura de 12 min
Three thousand zettabytes. This monstrous amount of data is the conservative projection for the volume of all the world’s existing data by 2040. If you sat down to watch three thousand zettabytes (3 x 1024 bytes) of 4k video, you would need nearly 50 billion years of couch time – that’s a lot of popcorn!
Data storage uses finite resources. Any device that uses flash memory stores data as electrical potential within minute transistors that are etched into silicon wafers. While the number of transistors per unit area of silicon has approximately doubled every two years since their invention, transistors have limits to their minimum size and maximum packing density. If projections hold true, our data boom could surpass the data space available in our supply of microchip-grade silicon.
A close-up of the internals of a silicon-based computer chip. Fuente: Flickr; Author Fritzchens Fritz. Licensed under CC0 1.0
Currently, digital data archives are stored in huge physical libraries, not on silicon but on magnetic tape. Compared to silicon, magnetic tape technologies are far less data dense, but far cheaper to maintain. Technology news outlet The Register breaks down the costs in detail here.
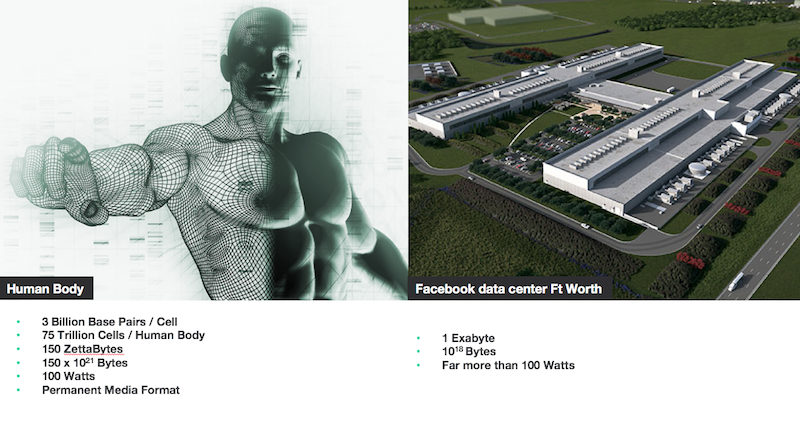
The biggest tape archive facilities can store an exabyte (1018 bytes) of data, but these facilities take up huge amounts of space, cost billions in upkeep, use considerable amounts of energy, and require the tapes to be copied around once every 3-10 years to ensure that the data is not lost due to degradation. Silicon may one day replace tape as the archiving medium of choice once maintenance costs fall, but it will only be sustainable in the short term – not a great property for an archive. In contrast, the DNA in one human body stores 150 zettaBytes (150 x 1021 bytes)!
DNA is nature’s way of storing data
Every feature and function found in the vast diversity of life on earth is encoded in a sequence of nucleic acids that provides instruction for a cell.
Due to its tiny size, data density, low energy requirements for storage, many thousand-year lifespan, and inherent data encoding properties, DNA-based data storage technologies are being developed by researchers as potential alternatives to current digital data archive technology. Instead of being stored as 1s and 0s, data can be stored as A, T, C or G nucleotides, which are then synthesised into long oligonucleotides.
When talking about DNA data storage, there are two measures to know – data density and data capacity. Data density describes how much data could theoretically be stored per gram with current methods. Data capacity describes how much data is successfully encoded or decoded in DNA at one time.
In theory, an upper data density limit of around a zettabyte (1021 bytes) could be stored in one gram of DNA. A DNA data archive smaller than your thumb could store 1.000 times more data than the largest data archive facilities today – meaning that at commercial pace, keeping up with the data boom would be trivial.
Theoretically, a zettabyte of data could be stored a 1 ml tube, whereas the largest magnetic tape storage units only store an exabyte. Fuente: Flickr; author: University of Michigan School For Environment and Sustainability.
Fuente: wkicommons. Author of the second image: Derrik Coetzee. Both licensed under CC BY 2.0.
Over the last 20 years, several proof-of-principal DNA data storage technologies have emerged showing how data can be encoded, and then efficiently decoded to retrieve the original data.
In 1999, the record for DNA data storage capacity encoded just a few words. Now, researchers working with Twist Bioscience are breaking new ground regularly. In July 2016, Microsoft and the University of Washington set a new record for DNA data storage capacity, encoding and decoding 200MB of data with perfect accuracy, including the Universal Declaration of Human Rights in over 100 languages!
Recently, in March 2017, a paper published in the journal Science used oligonucleotides synthesised by Twist Bioscience to set a record for data storage density by incorporating a data encoding technology that is usually used to stream accurate live video over the internet. Here we delve deeper into this new storage strategy.
Cracking Data Errors in DNA Data Storage
Incredible progress in a type of coding called error correction has been implemented widely in the digital data storage industry to mitigate damage to data caused by noisy storage media. Many of the same error correction algorithms apply to DNA data storage as well to ensure that encoding and decoding data happens seamlessly. These algorithms work by storing data that does not encode any information, but can be used by a data decoder to detect and correct errors in binary data, without having to encode the data with significant overlap. The study of these error correction algorithms is called coding theory, and its application practiced widely on all personal computers and smartphones worldwide.
Like magnetic tape, for DNA data storage to be viable, digital data must be able to be encoded and decoded. Rather than encoding and decoding with 0s and 1s, known as binary coding, DNA storage applies quaternary coding, with A, C, G and T (the four building blocks of life that make up DNA). When the oligonucleotides containing encoded data are synthesized, an incorrect nucleic acid can occasionally be written into the strand (for example inputting a T instead of a G). Errors can also occur during the DNA sequencing step, where the encoding DNA sequence is read incorrectly (for example outputting a T instead of a G). Researchers are now applying the superior error-correction algorithms developed over decades to DNA data storage.
With coding theory, a CD can still play perfectly despite a scratch, and a poor internet connection can still deliver every frame of a video stream. Professor Yaniv Erlich of Columbia University, and Dina Zielinski previously of the New York Genome Center adapted a part of coding theory called “fountain codes” for use with nucleotide data in their recent paper published in the journal Science.
An Illumina MiSeq, a high throughput sequencing device that would be used to retrieve data stored in oligonucleotides. Fuente: Wikicommons, Author: Konrad Förstner
One solution for error correction when storing data on DNA requires the encoding pool of oligonucleotides to be designed with significant overlap in sequence. An incorrect base in one oligonucleotide could be correct in several others, for example, so the message can still be decoded error-free.
“Interest in storing digital data on DNA is growing exponentially, with some of the brightest minds in technology and healthcare investing in its advancement,” said Bill Peck, chief technology officer of Twist Bioscience. “The recent convergence of affordable DNA sequencing, scalability of our silicon-based DNA synthesis technique and the robust coding algorithms used routinely in the technology industry presents a new opportunity enabling DNA to become a viable data storage option. Using DNA as an archival technology avoids two key limitations of traditional digital storage media: limited lifespan and low data density.”
A DNA fountain sets a new-record for data storage density
Erlich and Zielinski were able to encode and perfectly decode a total 2,14 megabytes of computer data in DNA, including an entire computer operating system, and an Amazon gift voucher. While 2 MB of data did not approach record amount for DNA storage capacity, their storage strategy achieved a record-setting data density, cramming 215 Petabytes (1015 bytes) of data into one gram of DNA.
By adapting an algorithm called “fountain codes” to work with DNA-based data, the “DNA Fountain” was developed. In short, this new algorithm breaks the data into small non-overlapping chunks and uses another algorithm central to fountain codes, called a Luby transform, to compress the chunks into the final data that is encoded into DNA.
The Luby transform works by employing a pseudorandom number generator to select a random number of data chunks, and compress them together to form “droplets.” Each droplet is seeded, so the same pseudorandom number generator can be used in the decoding step to denote how many chunks of original data are compressed in the droplet, and their origin. For a description of how seeding and pseudorandom number generators work, check out this useful video from Khan Academy.
The droplet sizes are designed so their 1s and 0s can be mapped to A, T, C and G nucleotides that fit into a single oligonucleotide sequence. Fountain codes possess the important property of allowing any number of droplets to be produced. By producing enough droplets, each chunk of original data can be compressed many times in multiple droplets, causing redundancy in the encoding. Due to this redundancy, to deconstruct the original code without error, only a small percentage more droplets are required than original data chunks.
The result is an incredibly space-efficient algorithm that approaches a 1:1 number of data chunks to oligonucleotides required to accurately decode the dataset, each of which can be made with a high throughput DNA synthesis technology like that provided by Twist Bioscience.
As DNA fountain is randomly compressing binary data and converting it to nucleotide data, it will sometimes create sequences that are difficult for a DNA synthesis company to make, such as a large portion of the sequence being G or C nucleotides or multiple of the same nucleotides existing in a row. The DNA fountain algorithm constantly checks for these patterns that are difficult to synthesize, and automatically deletes offending sequences before trying again.
Using DNA Fountain, Erlich and Zielinski encoded six files. Their data included a $50 Amazon gift card, a minimalist computer operating system called KolibriOS, an image of The Pioneer Plaque, a PDF file containing the seminal publication on information theory that made computing possible, the 1895 film L'Arrivée d'un train en gare de La Ciotat, and an infamous computer virus called the zipbomb.
“We wanted to encode the zipbomb virus because viruses that infect humans are made of DNA. We thought that adding a computer virus to the DNA would be great fun,” commented Dr. Erlich.
In total, the six files were encoded as a pool of 72.000 oligonucleotides, all 200 bases in length, which were synthesized simultaneously using Twist Bioscience’s high throughput DNA synthesis platform. Each oligonucleotide contained 152 nucleotides of encoded data, 40 nucleotides of sequences required for Illumina high throughput DNA sequencing, and 8 nucleotides were used this to set up a second algorithm from coding theory called Reed-Solomon error correction that can also resolve errors from DNA synthesis and sequencing.
“We could not have done this experiment without DNA from Twist Bioscience,” commented Dr. Erlich. “I believe Twist is the only company making DNA of sufficient throughput for the purpose of data storage at this time.”
The 72.000 oligonucleotides encoding the stored data were sequenced. All six files, totalling 2,14 MB of encoded data, were decoded from the sequenced nucleotides without a single error. By extrapolating the density of the information stored, 215 petabytes of data could be stored per gram of DNA using DNA fountain – a data storage density that is unmatched by any other available data storage technology that exists today.
Finally, as a portion of the DNA used to store the data would be taken for sequencing every time it is decoded, the DNA must be duplicated periodically. The researchers also showed that the DNA could be copied almost indefinitely (2,28 quadrillion times) using the polymerase chain reaction, while still being able to retrieve all data with 100% accuracy.
This research helps cement DNA data storage as a viable solution for the future data boom. When exactly will we see DNA data storage replace tape technologies? That we cannot say for sure. However, DNA data storage is a field that is progressing rapidly, and has tremendous potential!
Cover image source: Flickr; Author: Christiaan Colen. Licensed under CC BY-SA 2.0
¿Qué piensa?
Me gusta
No me gusta
Me encanta
Me asombra
Me interesa
Lea lo siguiente
Suscríbase a nuestro blog y conozca las últimas novedades